

You might have used tools like Chat GPT and Bard to get human-like content and responses. This is just one example of an AI powered by Machine Learning. Ranging from virtual assistants to self-driving cars, estimating the time of arrival through GPS to nudge replies to emails, and everything in between, AI/ML-based models have penetrated almost every sphere of life. And, the process that fuels these algorithms is called data annotation.
Without properly annotated data, even the most advanced AI and ML algorithms would struggle to make sense of the overwhelming volumes of unstructured data available. Thus, labeled datasets enable machines to comprehend vast amounts of information, the way human brains do.
Data Annotation: The Bedrock of Machine Learning
Just as a human child is told the difference between a cat and a dog, a machine needs to be told what it’s comprehending and provide context in order to make decisions. Data annotation creates the link between data and machines. The tags, categories, labels, descriptions, and other such contextual elements serve as ground truth for the Machine Learning algorithms, based on which they can analyze and take actions. Using this information, the computers learn how to interpret raw, unseen data.
This annotated data enables the Computer Vision, NLP, Deep Learning models, etc. to learn from examples and generalize their knowledge to make accurate classifications and predictions. Here are some real-world applications of annotation in Machine Learning:
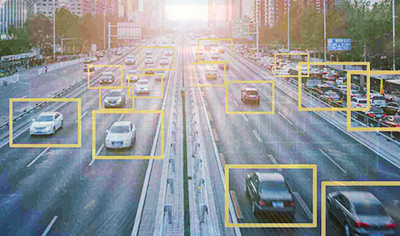
- Computer Vision for Autonomous Vehicles
Annotated data is vital to train Computer Vision-based models for self-driving cars. Millions of labeled datasets are used to help the algorithms detect and identify different objects on the road such as pedestrians, other vehicles, traffic signs, and road markings. Annotated data helps these autonomous vehicles make real-time decisions and navigate safely.
- Medical Image Analysis
Data annotation is essential for the analysis of medical images such as X-rays, MRI scans, and histopathology slides. Labeled data assists doctors in detecting abnormalities, diagnosing diseases such as cancer, neurological disorders, or cardiovascular diseases, and treatment planning. This leads to the early detection of diseases and helps in improving healthcare outcomes.
- E-commerce and Recommendation Systems
Annotated data is employed in recommendation systems to categorize and tag products, as well as to understand user preferences. This annotated data is then used to provide personalized recommendations, enhancing the user’s shopping experience. Other than this, businesses use AI for product listing, personalized marketing, managing large inventory, detecting illegal buying and selling, and facilitating seamless communication.
- Natural Language Processing (NLP)
In NLP applications like sentiment analysis, chatbots, and machine translation, data annotation is vital for tasks such as text classification, entity recognition, and sentiment labeling. This labeled data is crucial for training and developing models that can understand, analyze, and generate human language accurately.
- Image and Video Content Moderation
Social media platforms, content-sharing websites, and online forums use data annotation to detect and filter out inappropriate or harmful content, such as hate speech, nudity, or violence. Moderation models rely on annotated data to enforce community guidelines and maintain a safe environment.
These are just a few examples illustrating that data annotation services are pervasive across various industries and Machine Learning applications, enabling the training of accurate and effective AI models.
Challenges in Data Annotation
The data annotation process presents a number of cumbersome challenges, especially for companies with limited resources. Listed below are some of them:
-
Subjectivity
Subjectivity poses a significant challenge in the annotation process. It arises when human annotators are required to make judgments that depend on their personal interpretation or perspective. This challenge is particularly evident in tasks such as object detection, image classification, and sentiment analysis. Key aspects of subjectivity include:
- Ambiguity – Providing precise annotations to inherently ambiguous data can be challenging. For instance, in image classification, deciding whether an image contains a ‘cat’ or a ‘dog’ can be subjective, especially when the animal is partially hidden or the image quality is poor.
- Inter-Annotator Agreement – Different annotators might add different interpretations or labels for the same data. Measuring and improving inter-annotator agreement is essential to ensure data consistency.
- Cultural and Contextual Variability – Annotations can vary based on cultural and contextual factors. For example, a gesture or symbol may have different meanings in different cultures, leading to inconsistencies in annotation.
- Temporal Variability – The perception of data can change over time. Language evolves, and social or cultural contexts shift, making it challenging to ensure consistent annotations, especially in historical datasets.
As subjectivity is a persistent problem, a data annotation outsourcing company follows clear and detailed annotation guidelines, offers ongoing training and feedback to its team, and uses multiple annotators to achieve consensus on difficult cases. Additionally, they perform regular quality control checks and monitoring to identify and rectify inconsistencies.
-
Consistency
Maintaining consistency in data labeling is a critical challenge. It’s closely related to subjectivity and can considerably impact the quality and performance of Machine Learning models. Key aspects of consistency include:
- Temporal Consistency – As data evolves, annotations may need to be updated or revised, requiring a system for tracking and managing version changes.
- Annotator Variability – Different annotators might take guidelines differently or evolve their understanding over time. This can lead to inconsistent annotations within the same dataset.
- Consistency Across Data Types – Maintaining consistency can be particularly challenging when working with diverse data types including text, images, audio, etc., which may require specialized annotation guidelines.
- Complex Labeling Schemes – In tasks like fine-grained image classification, complex labeling schemes with multiple classes can lead to inconsistencies.
Regularly reviewing and updating annotation guidelines, conducting frequent quality control checks, and keeping clear communication among annotators can help address consistency issues. Employing an experienced data annotation specialist who understands the nuances of the task can also contribute to improved consistency.
-
Quality Control
Ensuring the quality of annotations is a central challenge. Poor-quality annotations negatively impact the performance of Machine Learning models, which can be costly to rectify. Key aspects of quality control include:
- Annotator Training – A team of annotators and data professionals need to be trained thoroughly in understanding the annotation guidelines and using data labeling tools effectively.
- Quality Assurance – Implementing quality assurance measures to catch errors or inconsistencies in annotations is essential. This may involve random sampling for review, cross-checking between annotators, and feedback loops.
- Feedback Mechanisms – Establishing feedback mechanisms to address issues, provide clarifications, and improve the quality of annotations over time is important.
- Iterative Process – Data annotation is often an iterative process. AI/ML models built on initial annotations can highlight issues that need to be addressed in subsequent iterations.
Quality control should be an ongoing process for companies looking to harness the potential of AI and ML models, involving continuous feedback, training, and regular audits. It’s also important to maintain open lines of communication between annotators and project managers to address issues as they arise.
-
Label Imbalance
Label imbalance occurs when there is a significant disparity in the number of samples across different classes or categories. This is a common challenge in classification tasks and can lead to biased models. Key aspects of label imbalance include:
- Underrepresented Classes – Some classes may have very few examples, making it challenging for Machine Learning models to learn from these classes effectively.
- Overrepresented Classes – Conversely, overrepresented classes may dominate the model’s training and lead to biased predictions.
- Impact on Model Performance – Label imbalance can result in models with poor performance on underrepresented classes and an overall skewed accuracy.
To address label imbalance, techniques like oversampling, under-sampling, and using class-weighted loss functions can be employed during model training. A professional data annotation company can assist you in mitigating this challenge by collecting more data for underrepresented classes.
-
Bias
Bias in data annotations is a critical ethical and fairness challenge. Annotators may inadvertently introduce their own biases into the data, leading to biased machine-learning models. Key aspects of bias include:
- Cultural Bias – Annotators may unknowingly favor certain cultural perspectives or references, leading to biased annotations.
- Socioeconomic Bias – Economic or social biases can influence annotations in areas like sentiment analysis or image labeling.
- Labeling Biases – Biased interpretations or labeling may disproportionately affect specific groups, leading to fairness issues.
Addressing bias requires diverse and inclusive annotation teams and regular training on recognizing and mitigating bias during model development. It’s also important to have clear ethical guidelines and policies in place to ensure that data annotations are free from discrimination.
Closing Thoughts
AI/ML applications powered by data annotation are already disrupting businesses across a diverse range of industries, for good. And given the complexity and intricacy of the process, challenges are bound to arise. Mitigating them requires careful planning, ongoing quality control, effective communication with experts, and a commitment to ethical and unbiased data annotation practices. These efforts are essential for ensuring the success and fairness of Machine Learning models. Other than this, data annotation outsourcing is a Holy Grail that companies can rely upon to get high-quality, unbiased, and precise training data at all times.
